












Neste post, vamos explorar 5 aplicações essenciais de Visão Computacional que você precisa conhecer para potencializar sua estratégia de negócio ao mesmo tempo em que automatiza e aprimora seus processos. Também vamos falar sobre como bibliotecas open-source de Visão Computacional podem transformar indústrias contando com o apoio do Python e Machine Learning.
Neste artigo você vai ver:
Explorando o poder da Inteligência Artificial: Visão Computacional pode transformar indústrias
Atualmente, a Visão Computacional é uma das áreas mais interessantes e impactantes da Inteligência Artificial (IA). Ela permite que os computadores possam “ver” e interpretar o mundo ao nosso redor. Isso é possível graças ao uso de algoritmos e técnicas de Aprendizado de Máquina (Machine Learning) que ajudam os computadores a interpretar e compreender imagens e vídeos.
O Aprendizado de Máquina e a Visão Computacional estão intrinsecamente ligados, uma vez que o Machine Learning é a base de muitas das aplicações em Visão Computacional. A Visão Computacional é uma área de rápido crescimento e evolução, que está transformando indústrias e criando novas possibilidades em muitas áreas diferentes.
Veja na prática: Como o Machine Learning ajudou a controlar a entrada e saída de cargas portuárias com mais segurança e confiabilidade, de forma ágil e consistente

Para que os computadores possam interpretar e compreender imagens e vídeos, é necessário treinar modelos em conjuntos de dados rotulados, que consistem em imagens e suas respectivas classes.
Os modelos de Machine Learning aprendem a partir desses dados e, com o tempo, se tornam capazes de reconhecer padrões nas imagens e classificá-las em diferentes categorias. Dessa forma, a utilização desses algoritmos permite que os computadores possam realizar tarefas que, anteriormente, eram exclusivas de seres humanos, como o reconhecimento de objetos, a detecção de faces e a identificação de anomalias em imagens médicas, por exemplo.
>> Veja também: Como se manter um desenvolvedor curioso e criativo?
5 aplicações essenciais de Visão Computacional
1. Detecção de objetos
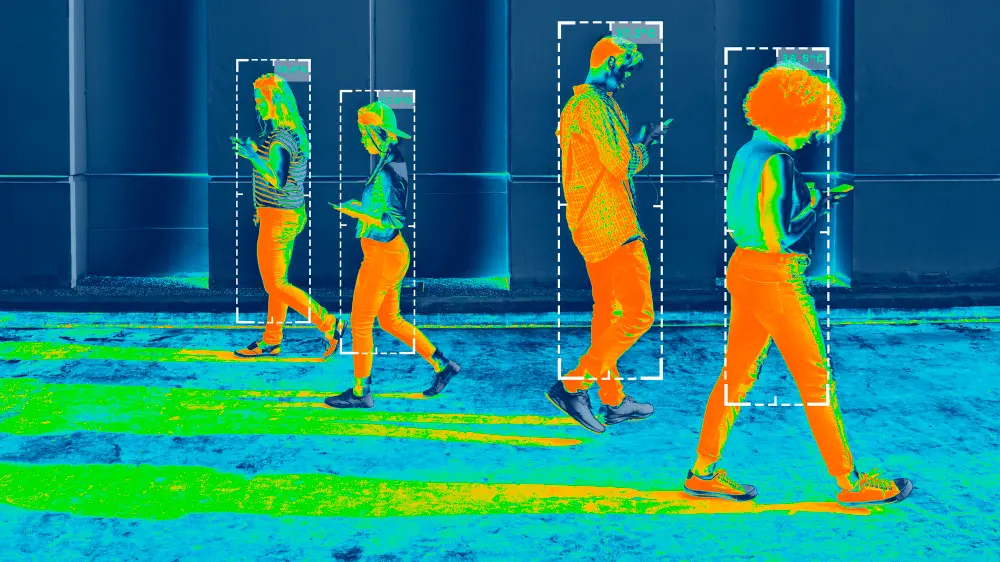
A detecção de objetos é um dos principais desafios em Visão Computacional. Ela é uma tarefa que envolve a identificação e localização de objetos em uma imagem ou vídeo. Ela é usada em muitas aplicações, incluindo sistemas de segurança, análise de imagens de satélite, detecção de placas veiculares, entre outras.
Existem várias técnicas e frameworks gratuitos em Python que permitem a construção de modelos de detecção de objetos, incluindo o TensorFlow, PyTorch e Keras.
Uma das técnicas mais populares para a detecção de objetos é o uso de Redes Neurais Convolucionais (CNNs). As CNNs são uma técnica de Machine Learning que pode ser usada para treinar um modelo capaz de identificar objetos em uma imagem.
O modelo é treinado em um conjunto de dados rotulados, que consiste em imagens com objetos identificados e suas localizações exatas na imagem. O modelo, então, pode ser usado para detectar objetos em novas imagens.
Outro exemplo de arquitetura de CNN popular para detecção de objetos é a YOLO (You Only Look Once). Essa arquitetura é conhecida por sua rapidez e precisão, permitindo a detecção em tempo real de múltiplos objetos em uma única imagem. A YOLO utiliza uma abordagem de detecção de objeto baseada em grades, onde a imagem é dividida em células e o modelo é treinado para identificar objetos em cada célula.
Essa técnica tem sido amplamente utilizada em aplicações de segurança como em sistemas de vigilância por vídeo, mas também tem sido adotada em outras áreas, como automação industrial e veículos autônomos.
2. Reconhecimento facial

O reconhecimento facial é uma aplicação popular de Visão Computacional que envolve a identificação de indivíduos em imagens e vídeos.
O reconhecimento facial é usado em muitas áreas, incluindo segurança, marketing e entretenimento. Bibliotecas como o OpenCV, DLib e DeepFace permitem a fácil utilização do reconhecimento facial em Python, a partir do treinamento de novos modelos ou da aplicação de modelos pré-treinados.
Uma das técnicas pioneiras e mais populares para o reconhecimento facial é o uso de algoritmos de detecção de características faciais, como o Eigenfaces e o LBPH (Local Binary Patterns Histograms). Esses algoritmos são usados para treinar modelos capazes de identificar características faciais em uma imagem e determinar a identidade da pessoa com base nessas características.
Já a DeepFace é um dos exemplos de bibliotecas de reconhecimento facial e análise de atributos faciais para Python, que inclui modelos de IA para reconhecimento facial e faz todo o processo em segundo plano. Com apenas algumas linhas de código, você pode executá-la e ter acesso a recursos como verificação de rosto, reconhecimento facial, análise de atributos faciais e análise facial em tempo real.
Além disso, você não precisa de conhecimento aprofundado sobre o funcionamento desses processos de detecção/reconhecimento/verificação facial uma vez que, para usar a maioria dessas bibliotecas, basta apenas indicar a localização das imagens que você deseja processar em seu computador.
3. Reconhecimento Ótico de Caracteres (OCR)

Outra aplicação importante de Visão Computacional é o Reconhecimento Ótico de Caracteres (OCR), que permite que os computadores possam “ler” e interpretar o texto em imagens e documentos digitalizados. Isso é especialmente útil em indústrias como a de finanças e a de saúde, onde há uma grande quantidade de documentos em papel que precisam ser digitalizados e processados.
Algumas ferramentas úteis para realizar a leitura de caracteres incluem o PyTesseract, OCRopus e EasyOCR.
O OCR funciona através do uso de algoritmos que segmentam uma imagem em áreas onde há texto e, em seguida, usam técnicas de processamento de imagem e Machine Learning para identificar e reconhecer os caracteres em cada área. O OCR pode ser usado em uma ampla variedade de tipos de documentos, incluindo faturas, recibos, notas fiscais, formulários, passaportes e até mesmo em capturas de tela de páginas da web.
Ele também tem o potencial de permitir o acesso mais fácil e rápido a informações valiosas em documentos importantes, melhorando a eficiência operacional e a tomada de decisões.
Um dos softwares de OCR mais populares é o PaddleOCR, desenvolvido pela empresa chinesa Baidu. Ele é baseado em uma arquitetura de rede neural profunda chamada EAST, que é capaz de detectar e reconhecer texto em imagens em tempo real.
O PaddleOCR é treinado em um grande conjunto de dados para reconhecer uma ampla variedade de caracteres em diferentes idiomas e formatos, incluindo letras, números, símbolos e caracteres especiais. Ele é capaz de identificar o texto em diferentes fontes, tamanhos, cores e orientações, tornando-o uma ferramenta útil em várias aplicações, como reconhecimento de placas de carro, processamento de documentos, reconhecimento de letras manuscritas, entre outras.
O PaddleOCR também é uma opção popular devido à sua facilidade de uso e à disponibilidade de código aberto.
Veja uma aplicação na prática: IA ajuda a controlar a entrada e saída de cargas portuárias
4. Classificação de imagens
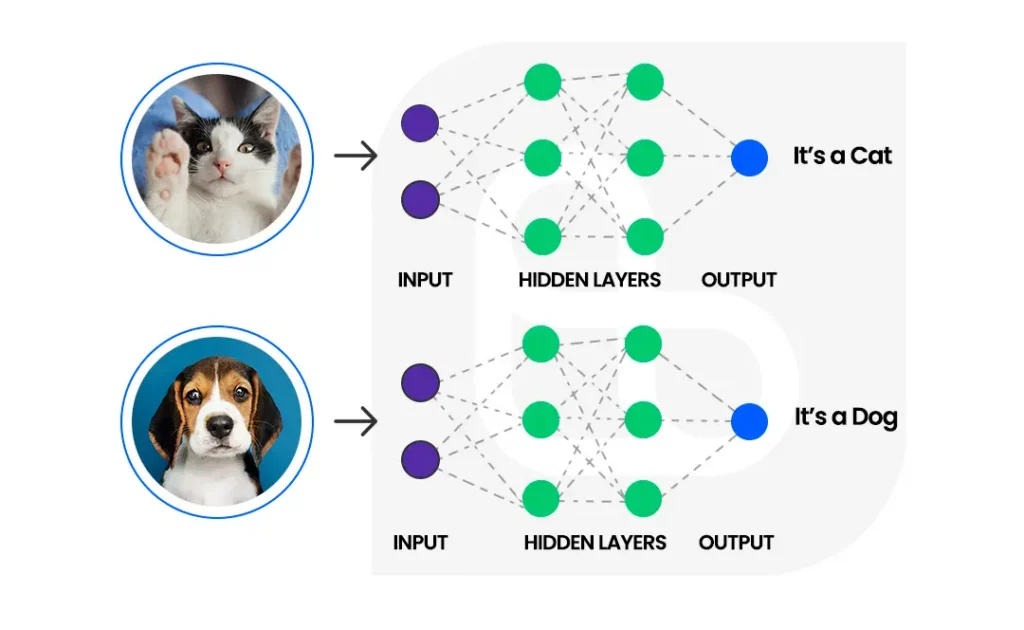
A classificação de imagens é outra aplicação de Visão Computacional e Machine Learning. Ela envolve a categorização de imagens em diferentes classes com base em seu conteúdo visual.
Essa técnica é amplamente utilizada em reconhecimento de objetos, identificação de doenças em plantas, identificação de espécies de animais e muito mais. Ela é uma tarefa que pode ser facilmente automatizada e aprimorada, permitindo que as empresas obtenham insights valiosos de dados visuais de forma mais eficiente. Algumas das principais bibliotecas para classificação de imagens em Python são Keras, TensorFlow e PyTorch.
A classificação de imagens é feita por meio do treinamento de um modelo de Machine Learning em um conjunto de dados rotulados. Esse conjunto consiste de imagens que foram previamente categorizadas, no qual o modelo aprende a reconhecer padrões visuais e características distintas para cada categoria. Uma vez treinado, o modelo pode ser usado para classificar novas imagens de acordo com suas respectivas categorias.
Uma das abordagens mais populares para a classificação de imagens é a utilização de redes neurais convolucionais (CNNs). As CNNs são particularmente eficazes na extração de recursos visuais únicos e complexos em uma imagem, tornando-as ideais para tarefas de classificação de imagens.
Um exemplo comum de aplicação de classificação de imagens é a classificação de imagens médicas. Através do treinamento de algoritmos de Machine Learning em um grande conjunto de dados de imagens médicas rotuladas, é possível criar modelos que podem identificar doenças ou anomalias a partir de radiografias, tomografias e ressonâncias magnéticas.
Esses modelos podem ser usados por médicos e especialistas em saúde para auxiliar no diagnóstico e tratamento de pacientes, permitindo uma detecção mais rápida e precisa de anomalias ou doenças. Essa aplicação tem um grande potencial para salvar vidas e melhorar a qualidade de vida dos pacientes.
5. Segmentação de imagens

A segmentação de imagens é uma técnica de Visão Computacional que consiste em dividir uma imagem em várias regiões ou segmentos com características visuais similares. Esse processo é muito útil para a identificação e extração de objetos específicos em uma imagem, permitindo que eles sejam isolados e analisados separadamente a nível de pixel.
Existem várias redes neurais que podem ser utilizadas para segmentação de imagens. Algumas das principais são a Fully Convolutional Network (FCN), a U-Net e a Mask R-CNN.
A FCN foi uma das primeiras redes neurais feitas para isso e é baseada em uma arquitetura de rede totalmente convolucional. Já a U-Net usa um esquema de codificador-decodificador para segmentar imagens. Por fim, a Mask R-CNN é mais nova e usa tanto a detecção de objetos quanto a segmentação de instâncias juntas.
Uma das aplicações mais comuns da segmentação de imagens é na indústria automotiva, onde é possível segmentar diferentes partes do carro em imagens para identificar possíveis defeitos ou falhas na produção.
Além disso, a segmentação de imagens também é usada em tecnologias de reconhecimento de caracteres e em sistemas de segurança, onde é possível segmentar objetos em imagens de vídeo para identificar ameaças e comportamentos suspeitos.
>> Veja também: Você sabia que programar é considerado uma arte?
Aplicando a visão Computacional na prática
A LATAM está implementando tecnologia de Inteligência Artificial no aeroporto de Guarulhos, o seu principal hub (centro de conexões de voos), para aprimorar o atendimento ao cliente.
Em parceria com o LATAM Labs e a Proc Group, a inovação utiliza nove câmeras para monitorar o check-in doméstico, transformando o fluxo e os movimentos dos clientes em dados para melhorar a eficiência operacional e a experiência do cliente nos aeroportos. As informações coletadas permitem a análise da demanda, qualidade dos serviços, capacidade e produtividade da equipe.
O objetivo é gerenciar eficientemente os canais de atendimento, reduzir o tempo de espera nas filas e melhorar a experiência do cliente. A LATAM assegura o cumprimento da Lei Geral de Proteção de Dados (LGPD) ao não ter acesso às imagens das câmeras, apenas aos dados processados pelo software.
Conclusão: Alavancando o poder de Aprendizagem da Máquina e Python para a Visão Computacional
A Visão Computacional é uma área promissora que continua sempre a evoluir e a inovar a passos largos. Ela utiliza o Aprendizado de Máquina e o Python (entre outras linguagens de programação) para criar soluções avançadas e precisas que aumentam a eficiência, reduzem custos e melhoram a qualidade do serviço prestado.
Desde a detecção de objetos e reconhecimento facial até a identificação de padrões em grandes conjuntos de dados, a Visão Computacional oferece uma ampla variedade de aplicações práticas que podem potencializar sua estratégia de negócio e alcançar resultados eficientes.
Além disso, a Visão Computacional está se tornando cada vez mais acessível, graças à disponibilidade de conjuntos de dados públicos, bibliotecas de código aberto e plataformas em nuvem que permitem a construção de modelos de forma rápida e fácil.
Com o avanço da tecnologia, é possível que em um futuro próximo tenhamos aplicações ainda mais sofisticadas e precisas, o que abrirá novas oportunidades para as empresas se diferenciarem em seus respectivos mercados.
Se você está interessado em aprender mais sobre a Visão Computacional, há uma série de recursos disponíveis online, incluindo tutoriais, cursos e comunidades de desenvolvedores que podem ajudá-lo a começar.
Gostou dessas dicas de visão computacional? Aproveite para ver o texto: Confira 4 dicas de automação de tarefas com Python.


